
Why Most Health Studies Don’t Apply Equally to Everyone
Health studies often report clear results—but those results don’t apply equally to everyone. A closer look at how study design limits generalizability and how to read health claims more carefully.

The assumption we make
When a study reports that a new drug reduces cardiovascular risk by 30%, or that a specific diet improves metabolic markers, it’s natural to assume those findings apply to everyone. The assumption feels reasonable—after all, if the study was rigorous and the results were statistically significant, shouldn’t the conclusions hold across the board?
Not necessarily. Research findings apply most reliably to populations that closely resemble the people who were actually studied.
The leap from ‘this worked in a study’ to ‘this will work for me’ is small, but it’s often unjustified. This intuition gap is a major reason health studies are misunderstood—not because the science is wrong, but because its scope is far narrower than we tend to assume.
Generalizability: the question studies have trouble answering
In research, the ability to apply results beyond the study population is called generalizability, or external validity. A highly generalizable study produces results that hold across different ages, sexes, genetic backgrounds, and health conditions. When generalizability is limited, findings may only apply to people who closely resemble the study participants.
Internal validity—whether a study correctly measured what happened within the trial–is usually prioritized. External validity is messier and usually harder to achieve. Designing a study that's both tightly controlled and broadly representative is extremely difficult. As a result, most trials optimize for clarity at the cost of generalizability.
Who actually gets studied
Clinical research rarely captures the full diversity of the population it aims to treat. This is driven by practical constraints. Researchers try to reduce variability, minimize risk, and increase the likelihood of detecting an effect. Studies require time and resources, so maximizing the chance of a clear result is essential.
For these reasons, study participants are often younger, healthier, and less medically complex than real-world patients. Between 2015 and 2019, 78% of participants in U.S. drug trials were white, with even higher proportions in certain therapeutic areas. Cardiovascular trials were approximately 90% white, while neurology trials were around 81% white. Women were historically excluded from many trials and have only recently achieved proportional representation overall—though gaps persist, particularly in cardiovascular research. Older adults, people with multiple chronic conditions, and pregnant individuals are routinely underrepresented or excluded altogether.
Randomized controlled trials also require consent, meaning they can’t be perfectly random. Many are conducted at urban academic medical centers, which can limit participation from rural populations. Some eligible patients decline to participate. As a result, the demographics of the final study population often don’t reflect the population the treatment will ultimately serve.
When a study population is narrower than the real-world population, applying its results broadly requires inference, not direct evidence.
Biological variation is the rule, not the exception
This variability isn’t noise; it reflects fundamental biological differences. Genetic variation affects drug metabolism. Aging alters kidney and liver clearance. Body composition changes how drugs are distributed. Environmental exposures shape disease risk long before treatment begins.
Health studies often attempt to control for this variation to isolate a clear signal, which can be helpful for understanding mechanisms. But in doing so, they can obscure just how much responses vary in the real world.
If you want a faster way to read health studies without oversimplifying them, subscribers get a free guide: How to Read a Health Study in 10 Minutes.
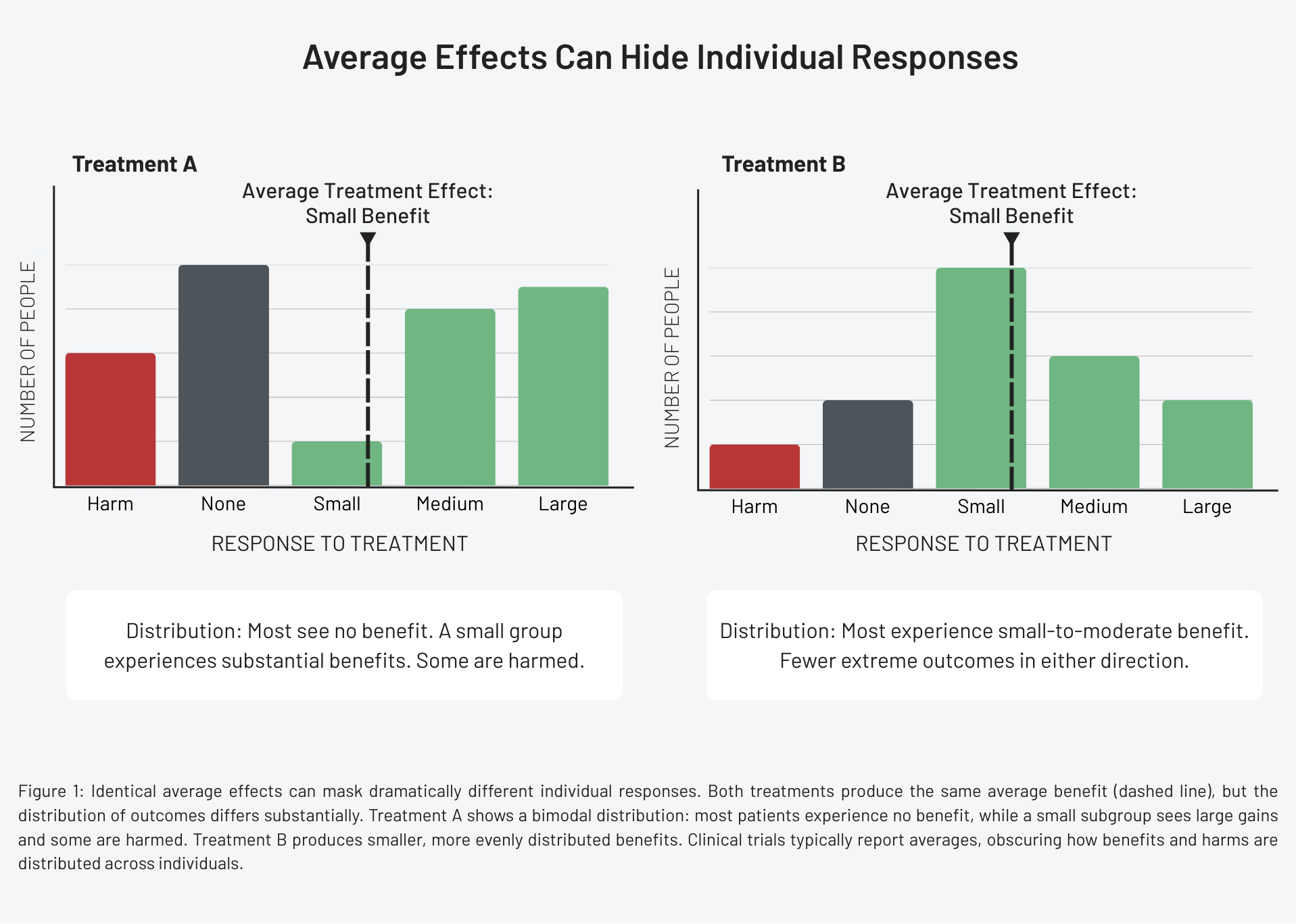
Average effects hide individual responses
An average treatment effect answers one question: was there a difference between groups? It does not tell us how many people benefited, how large the benefits were for those who did, who didn’t benefit at all, or who was harmed.
Two treatments with identical average effects can have completely different response profiles. One might benefit a small subgroup dramatically but do nothing for most. Another might produce modest benefits across many people. From the patient’s perspective, these scenarios are not equivalent. From the perspective of a p-value, they can look identical.
Blood pressure-lowering therapies illustrate this well. On average, reducing blood pressure lowers the risk of stroke and heart attack. Yet individual responses vary widely. Some patients experience substantial reductions with minimal side effects. Others see little change. Some develop dizziness, kidney dysfunction, or electrolyte imbalances that outweigh the benefits. Responses can vary depending on age, pregnancy status, and coexisting health conditions.
Clinical trials typically report the average effect. They rarely show the full distribution of responses. The average conceals the reality that benefits are not evenly shared and harms often cluster within specific subgroups.
The treatment ‘works,’ but not equally.
Exclusion criteria do more than you think
Exclusion criteria are designed to protect patients and simplify interpretation. But they also limit what the evidence can tell us. By excluding people with a particular disease, those taking certain medications, or individuals with prior adverse reactions, studies remove many of the patients clinicians routinely treat. The resulting evidence describes an idealized patient, not a typical one.
When treatments move from trials into practice, clinicians are forced to extrapolate. This extrapolation is necessary, but it’s not the same as evidence. When pregnant people are excluded from studies, for example, drug labels often state that effectiveness hasn’t been evaluated during pregnancy. This creates a cascade: no data leads to limited approval, which leads to restricted access.
This isn’t a failure of science, it’s a design constraint.
It’s tempting to frame these limitations as flaws, but they’re better understood as tradeoffs. Science operates under constraints: time, cost, ethics, and feasibility. It’s not possible to study everyone, everywhere, under every condition.
Researchers design studies to answer specific questions as clearly as possible. Problems arise when those limitations are minimized and results are treated as universally applicable.
What better evidence would look like
More generalizable evidence would include broader enrollment, longer follow-up periods, pre-specified subgroup analysis, and real-world data collected after approval. It would also involve clearer communication about uncertainty: who was studied, who wasn’t, and where conclusions may not hold.
No single study can achieve this. But bodies of evidence can. When findings are replicated across different populations, settings, and study designs, confidence in generalizability increases. When they’re not, that’s important information too.
How to read health claims more carefully
When you encounter a health claim, a few questions can help determine how relevant it may be:
- Who was included in the study—and who was excluded?
- How similar are the participants to the people the claim is aimed at?
- Is the result an average effect, or are individual responses described?
- Has the finding been replicated across different populations?
These questions help separate evidence from overgeneralization.
Why this matters
Health decisions are personal, but evidence is generated at the population level. Confusing the two can lead to misplaced confidence, disappointment, and avoidable harm.
Understanding the limits of generalizability doesn’t weaken trust in science, it strengthens it. It replaces oversimplified certainty with appropriately scoped conclusions. The goal isn’t to make evidence say less, it’s to make it say exactly what it can—and no more.
References
- Representation and generalizability in clinical research: Back to basics, Journal of Clinical and Translational Science
- Why Diverse Representation in Clinical Research Matters and the Current State of Representation within the Clinical Research Ecosystem, Improving Representation in Clinical Trials and Research
- U.S. racial and ethnic participation in global clinical trials by therapeutic areas, Journal of Clinical Pharmacy and Therapeutics
- Target Validity and the Hierarchy of Study Designs, American Journal of Epidemiology
- Hypertension in adults: Initial drug therapy, UpToDate